第一篇博文小谈了一下分形。这次再说说分形更灵活的生成方法——无穷迭代。
理论
定义
$F(\mathbf{x} ) \text{:=} \lim_{k\to \infty } f^k(\mathbf{x} )$
其中$\mathbf{x}\in {{\mathbb{R}}^{n}}$,$f\left( \mathbf{x} \right)\in {{\mathbb{R}}^{n}}$,$f\left( \mathbf{x} \right)$定义在$\mathbf{d}$上,值域为$\mathbf{v}$。
${{\mathbf{D}}_{1}}:=\left\{ \mathbf{x}|F\left( \mathbf{x} \right)\ is\ exist\ and\ \left\| F\left( \mathbf{x} \right) \right\|<\infty \right\}$,${{\mathbf{V}}_{1}}:=F\left( {{\mathbf{D}}_{1}} \right)$
${{\mathbf{D}}_{2}}:=\left\{ \mathbf{x}|F\left( \mathbf{x} \right)\ is\ Multi-valued\ and\ \left\| F\left( \mathbf{x} \right) \right\|<\infty \right\}$,${{\mathbf{V}}_{2}}:=F\left( {{\mathbf{D}}_{2}} \right)$
$\mathbf{D}:={{\mathbf{D}}_{1}}\bigcup {{\mathbf{D}}_{2}}$,$\mathbf{V}:=F\left( \mathbf{D} \right)$
容易知道$\mathbf{V}\subset \mathbf{D}$。
如果将$\mathbf{D}$细分,它是由以下点集构成的:①不动点集,②压缩点集,③振荡点集,④*发散点集。
讨论
当$n=1$时,即便$f\left( \mathbf{x} \right)$是多项式,$\mathbf{D}$和$\mathbf{V}$也是比较复杂的。根据经验$\mathbf{V}$一般是单点集。
当$n=2$时,$\mathbf{D}$和$\mathbf{V}$就更加复杂了,而且还很有趣。为了方便讨论,将上面的定义写成显式的向量形式:\[f{{\left( {{x}_{1}},{{x}_{2}} \right)}^{T}}:={{\left( {{f}_{1}}{{\left( {{x}_{1}},{{x}_{2}} \right)}^{T}},{{f}_{2}}{{\left( {{x}_{1}},{{x}_{2}} \right)}^{T}} \right)}^{T}}\],其中${{f}_{1}}$和${{f}_{2}}$都是普通的二元函数。当${{f}_{1}}$和${{f}_{2}}$满足柯西-黎曼方程时,这样生成的图形与通过复数生成的分形是一致的。本文中的分形图案主要是由不满足柯西-黎曼方程的${{f}_{1}}$和${{f}_{2}}$生成的,用这样方式生成的分形更加灵活有趣。
当$n=3$时,可以用这种方式生成三维分形。当$n>3$时,可以生成高维分形,但难以表达。
Mathemaitca代码

点此查看可复制的代码>>
漂亮的分形图案














又折磨电脑了?
互相折磨一下
n = 3; dt = 0.005;
(H = Piecewise[{{{2 #1, #2/2},
0 <= #1 < 1/2 && 0 <= #2 <= 1}, {{2 #1 – 1, (1 + #2)/2},
1/2 <= #1 <= 1 && 0 <= #2 <= 1}}] &;
data01 =
Flatten[ParallelTable[{i, j}, {i, 0, 1 – dt, dt}, {j, 0, 1/2 – dt,
dt}], 1];
data02 =
Flatten[ParallelTable[{i, j}, {i, 0, 1 – dt, dt}, {j, 1/2, 1 – dt,
dt}], 1];
data1 = Nest[Apply[H, #] &, #, n] & /@ data01;
data2 = Nest[Apply[H, #] &, #, n] & /@ data02;
Graphics[{{Red, Point[data1]}, {Green, Point[data2]}}])
这个代码有点渣 一个很大的问题是采样点太大了就乱了 而且运算很慢
老实说绿色部分其实完全可以不做迭代的 这样可以省去一半的运算量 既然是过去做的 就贴上来做个反面教材算了
H的定义的条件部分可以简化一下,此程序的这个区域上只写#1<=1/2和#1>1/2就行。
还有就是H的自变量可以定义成列表形式,这样后面就不需要使用Apply了。
ParallelTable,在建立小表时并没有优势,在这个例子中还没有Table来的快。对于并行计算来说,由于需要将计算分配到各个CPU去,要消耗一点时间,但对于庞大的计算时,这点时间是可以忽略的。
优化程序主要在大循环里面。也就是这个程序计算data1和data2的地方。
贴一下你的代码让我也观摩一下。。。
你看看这两个代码,是否对你有帮助
★代码一,n=100时,可以节省34%的时间
Remove["Global`*"]
AbsoluteTiming[n = 100; dt = 0.005;
H[{x_, y_}] :=
Piecewise[{{{2 x, y/2}, x < 1/2}, {{2 x – 1, (1 + y)/2}, 1/2 <= x}}];
data01 =
Flatten[CoordinateBoundsArray[{{0., 1.}, {0., 0.5}}, dt, Center], 1];
data02 =
Flatten[CoordinateBoundsArray[{{0., 1.}, {0.5, 1.}}, dt, Center], 1];
data1 = Nest[H, #, n] & /@ data01;
data2 = Nest[H, #, n] & /@ data02;
Graphics[{{Red, Point[data1]}, {Green, Point[data2]}},
Frame -> True]]
★代码二,n=100时,也可以节省34%的时间
Remove["Global`*"]
AbsoluteTiming[n = 100; dt = 0.005; error = 10^-10;
H = {{x_, y_} :> Chop[{2. x, y/2.}, 10^-10] /; x < 1/2, {x_, y_} :>
Chop[{2 x – 1., (1. + y)/2}, 10^-10] /; x >= 1/2};
data01 =
Flatten[CoordinateBoundsArray[{{0., 1.}, {0., 0.5}}, dt, Center], 1];
data02 =
Flatten[CoordinateBoundsArray[{{0., 1.}, {0.5, 1.}}, dt, Center], 1];
data1 = ReplaceRepeated[data01, H, MaxIterations -> n];
data2 = ReplaceRepeated[data02, H, MaxIterations -> n];
Graphics[{{Red, Point[data1]}, {Green, Point[data2]}},
Frame -> True]]
谢谢野鹤了 但是最后发现这个图好像没有什么内容了
嗯。所有点都被压缩到{0,0}点了。
mathematica吧的吧主好像说过Remove可能会造成某种反效果 他给我看的链接我真心没看懂 野鹤 你怎么看?
那你也给我一个链接啊。 ;
;
Remove是完全删除符号,使得Mma都不认识它了。Clear是清除符号已经被赋的值,Mma还认识它。给你个例子可能会好些:
Clear[x, y, z];
abc = {x, y, z};
x = 3;
Clear
x = 3;
abc
Remove
x = 3
abc
假如我要清除a (i[Element]J1)的值又要保留a
(i[Element]J1)的值又要保留a 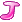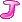 (i[Element]J2)的值(J1,J2为指标集)那该怎么做?
(i[Element]J2)的值(J1,J2为指标集)那该怎么做?
另外还是说一句 给代码的时候最好也告诉读者运行这个代码需要多少时间 这很重要!
这个就比较费劲了,还需要把自己电脑的配置贴上才行。
只告诉别人程序在自己电脑上跑了多长时间,也没什么意义。
特别是在论文的数值算例中,若需要强调运行时间,一定得有机器配置才靠谱。
比如一段程序在天河二号上一秒跑完,在我电脑上可能就需要跑一年。